
In my years of experience in helping businesses navigate technical due diligence during software evaluations, I'm finding there are repeated concerns that arise around critical elements such as performance and scalability. For instance, in the world of incentive compensation, one question we commonly receive is: "How long will my calculation process take in your solution? The answer is almost always “It depends…”. While this is not an unreasonable answer, because it does really depend on many factors and levers, it can sound evasive and leave both business and technical stakeholders wanting for more concrete details. In this blog, I will shed light on the various factors that contribute to a critical element in any technical due diligence: batch data processing performance and guidance on how business and technical buyers should expand their evaluation..
Debunking the myth of Batch Data Processing
In the realm of Incentive Compensation, batch data processing is a method of collecting large chunks of interdependent data with high correlation from upstream source systems, processing these chunks of data against established incentive rule sets, and then integrating the calculated results into downstream systems for further processing. One should always think of batch data processing as an end-to-end process that is horizontally scalable and multithreaded, and not just limited to calculations. This is because business process SLAs are inadvertently tied to data readiness, both from the input and output side. In other words, a successful and performant calculation process is largely dependent on the readiness of the upstream data. Furthermore, apart from the time it takes to integrate and calculate a specific data set in a particular period, practitioners must also ensure performance remains consistent every single period, as this directly impacts business process SLAs. As a result, one should place as much importance on consistent performance period over period rather than just the time it takes to process a singular data set in a particular period.
The 3-legged Stool of Batch Data Processing
To simplify and visualize batch data processing, I view it as a 3-legged stool. All three legs have to be carefully balanced to achieve optimal results. The three legs are:
- Data (Client controlled)
- Configuration (Client & Vendor controlled)
- Software & Infrastructure (Vendor controlled)
Data: As the first and primary leg of the batch data processing performance, inbound data from upstream source systems plays a pivotal role in determining the timing and consistency of the process. With inbound data, practitioners need to consider the following aspects:
- Volume of inbound data, both in terms of the length (rows) and width (columns)
- Number of inbound data sources
- Frequency of inbound data imports
- Full snapshots vs. deltas
Note: these aspects can vary based on the source of the inbound data. For instance, data coming from a data warehouse or data lake may have a higher degree of data preparedness than data coming directly from the system of origin. That said, irrespective of where the data is being sourced from, the data management capabilities of the ICM vendor can greatly influence the preparedness of the data prior to it being processed for Incentives. For instance, Xactly Connect provides robust data transformation and prep capabilities, ranging from simple data validations that business admin teams can configure and manage, to complex data transformations that technical teams can develop using advanced tooling. Some examples of these transformations include delta processing of inbound data, combining multiple distinct data sources into a common inbound data interface, filtering of invalid data rows, and so on. A robust data management capability like Xactly Connect provides a unique opportunity to transform your data management practices rather than a lift and shift of your current processes. This ensures that the right volume and structure of data is being fed into the incentives calculation engine.
Configuration: Incentive rule configuration is another key aspect of a controlled, consistent and performant batch data processing. The complexity of the rules configuration has a direct impact on the performance and consistency of the rules evaluation and data processing. Granted the complexity of incentive rules configuration will be directly tied to business requirements, however it is also important to consider configuration guardrails and best practices specific to the vendor solution when configuring the incentive rules. Xactly Incent natively provides configuration guardrails as part of the application in order to ensure that the implementation teams do not stray off of best practices, as opposed to a fully flexible canvas where best practices and guardrails can often be missed. Adhering to a guardrails and best practices based incentive rules configuration methodology is imperative to ensure a performant and consistent batch data processing environment.
Software & Infrastructure: As the third and equally important leg of batch data processing, scalable and performant software and infrastructure is critical in ensuring that data processing runs smoothly and consistently. While fully in the vendor’s control, both the application software and the underlying infrastructure components need to work seamlessly together in order to offer a highly performant batch processing environment. Key considerations include:
- Is process parallelization built into the application logic?
- How does the application control and process periods?
- Is the batch data processing performed on the relational database or on a high performance computing layer?
- How scalable is the underlying infrastructure?
Xactly Incent offers a state of the art calculation engine that is optimized both from the application logic layer as well as the infrastructure layer. The application logic offloads calculation processing workloads seamlessly to in-memory processing nodes operating on a high performance computing layer. Additionally, the application logic natively parallelizes database write operations once the calculated results are processed.
Each tier of the back-end infrastructure is fully redundant, secure and auto-scaled based on the customer workload.
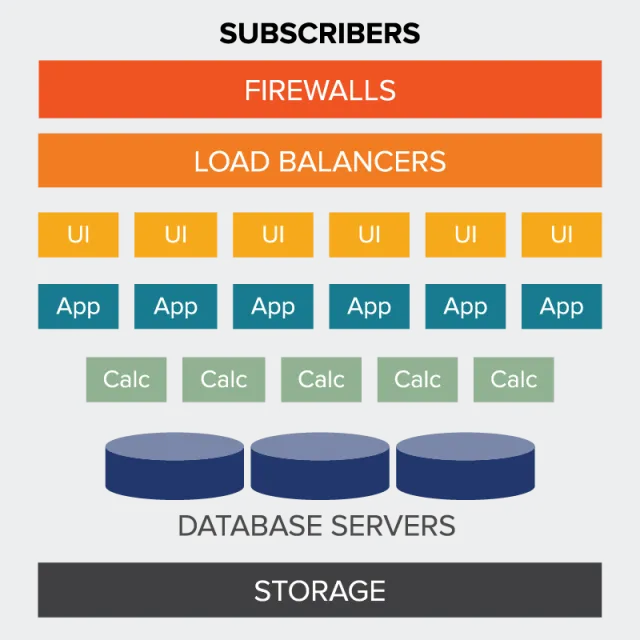
This allows Xactly Incent to manage some of the largest calculation processing workloads in the industry as is evident from the following chart:
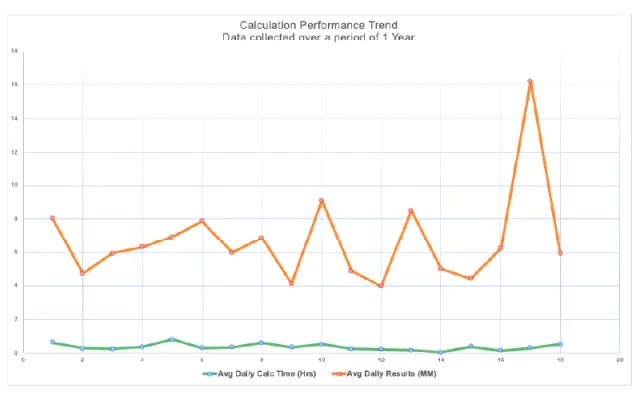
The above chart compares the batch data processing times with the average daily number of results being processed in Xactly Incent for the top 18 customers. While there is variability in the number of results processed which is tied to customer requirements, the average daily processing time remains consistent across the board. This is due to the highly scalable and performant calculation engine of Xactly Incent that seamlessly matches the workload demands of customers.
To conclude, I hope this provides a much needed perspective on how to critically think about batch data processing for Incentive Compensation Management and how Xactly Incent can match the processing needs of small and large businesses alike in a dynamic environment.
If you’re evaluating an ICM solution and you’d like to learn more about how we support customers in the ways I’ve outlined in this blog, please request a demo HERE.


